面对日益竞争激烈的移动金融服务场景,如何快速且准确地将合适的产品、服务触达合适的用户成为营销运营的一个核心课题。
在蚂蚁的投放营销活动过程中,一方面期望产品服务能够触达更多用户,另一方面希望触达的用户有较高的点击率和转化率。面对成千上万业务场景的竞争,需要有一套系统来辅助每个业务找到它们各自潜在的高价值用户,以提高流量的使用效率。
基于上述问题,蚂蚁智能引擎团队和流量运营技术团队共同打造了哈勃智能人群平台,现已包含六大功能:标签圈人、算法圈人、实时标签能力、人群管理能力以及后期的人群洞察能力和效果分析。通过算法赋能,哈勃智能人群平台已具备事前用户偏好理解、事中人群定向、事后归因分析等全链路辅助功能,本文将介绍哈勃后台算法的三代体系更迭。其中,相关工作现已发表在KDD 2020 Applied Data Science(Hubble: an Industrial System for Audience Expansion in Mobile Marketing)与CIKM 2020 Applied Research(Two-Stage Audience Expansion for Financial Targeting in Marketing)。
问题定义
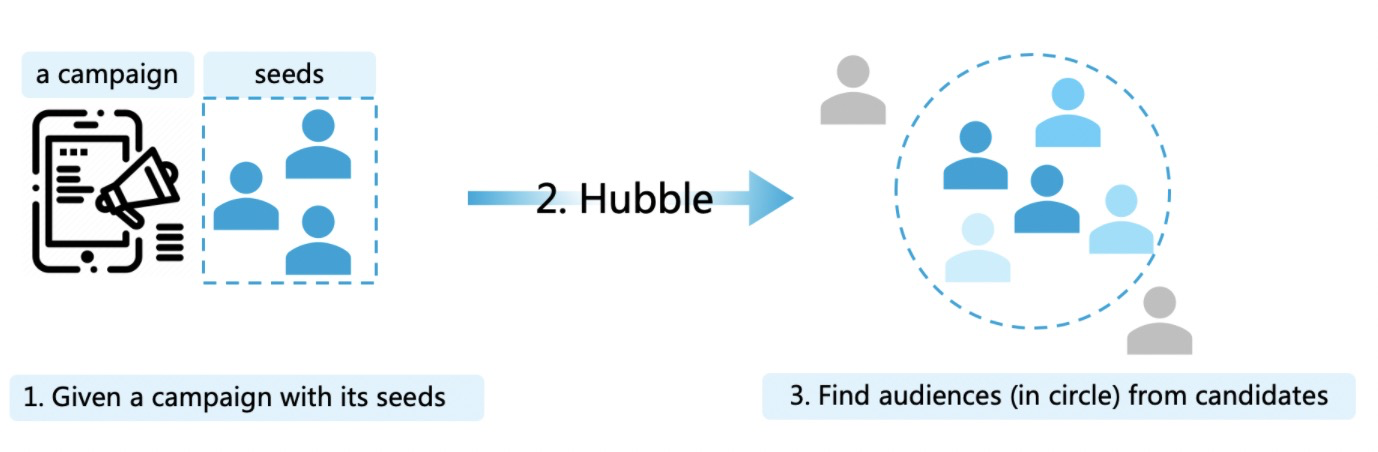
对于精准定向场景,问题描述如下图所示,给定一个营销投放活动(campaign)、种子用户(seeds)和当前业务的准入人群(candidates),人群定向目标是从准入人群中找到当前营销投放活动的目标人群(audiences),使得人群投放之后的点击率/转化率等指标最大化。解决这类问题的技术称之为audience expansion,又名lookalike。

从算法视角,我们既要确保平台有较高的定向效率(人群产出速度),又要确保人群定向效果(业务指标提升)。在调研了Pinterests[1]、Yahoo![2]、腾讯微信[3] 等公司公开的人群定向技术之后,我们发现现有的技术不能完美适配蚂蚁场景双效的保障。因此我们对哈勃后台的人群定向算法进行了3次升级:

第一代双塔模型是基于微软DSSM[4]开发的end-to-end模型。从第二代开始,我们重点考虑模型运行效率,将end-to-end算法结构解耦成异步的离线graph neural network(GNN)+在线轻量学习的结构。而在第三代中,为进一步提升圈人的时效性,我们额外引入投放中的实时反馈数据,并基于增量学习的方式融合种子用户和反馈数据的信息。
第一代:基于DSSM的audience expansion
这里采用微软提出的DSSM[4]模型是为了在常规二分类的基础上拆分user和scene/campaign各自的特征,核心是希望在每次营销活动投放的训练过程中能够更好地捕捉用户和该活动投放的关系。下图是我们使用的模型结构图:

DSSM是一个经典的双塔结构,这里的正样本为种子用户,而负样本由随机采样非种子用户得到。模型训练收敛之后,对准入人群(candidates)进行打分,分数越高表示用户对当前投放的兴趣越大。基于偏好分排序,我们就能找到当前投放的潜在用户。
在实际活动投放中,对比传统的GBDT,上述方法在点击率和转化率均有不错的提升。 但缺陷也很明显:(1)单次营销活动训练时间过长;(2)资源消耗高,从机器资源角度衡量,ROI并不理想。
考虑到上述缺陷,我们开始尝试2-stage的架构来取代end-to-end的方式,从效率和效果的双向角度考虑架构优化。
第二代:基于异步GNN+轻量学习的audience expansion

上图展示了哈勃平台算法的调用流程,整个算法流程分为“离线”和“在线”两部分:
· 离线AD-GNN(Adaptive and Disentangled Graph Neural Network)模型:基于时间顺序,我们将用户历史点击行为数据分成两部分,第一部分用于构建user-campaign的二部图,捕捉用户对不同营销活动的偏好,生成用户以及营销活动的抽象embeddings。对于第二部分数据,我们将用户点击的行为作为正样本,而曝光未点击的行为作为负样本。最后通过构建link prediction任务的方式来训练AD-GNN模型,从而得到campaign embedding和user embedding;
· 在线KD-AE(Knowledge Distillation based Audience Expansion)模型:一旦接收到一个人群定向的请求,系统会实例化一个轻量级KD-AE模型,用于找到当前活动的目标人群。类似上面提到的DSSM模型,该模型将用于学习用户(user)和当前投放(campaign)之间的偏好。
上述offline/online异步更新的方式很好地解决了算法执行效率的问题,下面我们主要介绍模型的具体实现是如何提高定向任务的效果。
离线AD-GNN模型
依托智能引擎团队自研的ALPS-GraphML平台,AD-GNN模型用于生成用户以及营销活动的抽象embeddings。建模需要解决两个挑战:(1)刻画用户和投放活动之间的复杂高阶交互信息;(2)解耦用户嵌入表达。为了解决第一个挑战,我们构建了一个用户和投放活动的二部图,使用图神经网络的方式来刻画复杂高阶交互关系信息。为了解决第二个挑战,我们使用解耦机制将用户的嵌入表达映射到不同channels上。为了进一步提高用户嵌入表达的质量,我们在解耦机制之前加入注意力机制,从而帮助模型消除一些噪音邻居带来的影响。下面具体介绍模型的各个模块。

Projection模块:对于图上每个节点,我们将其原始特征映射到K个不同的子空间。这K个子空间分别表示用户对于投放活动的K种不同的意图。对于节点i,把它映射到第k个子空间的公式如下:
Neighborhood Routing模块:为了构造解耦的user embedding,我们设计解耦机制迭代执行neighborhood routing。解耦机制开始时,使用Projection模块得到的z^k来初始化h^k。每次neighborhood routing过程分为两步。首先对于每个节点u计算使用它的邻居v来构造h_u^k的概率:

然后基于得到的邻居概率来更新:
Adaptive Breadth模块:注意到上述解耦机制没有考虑到可能存在噪音边,比如用户无意间点击了一些并不感兴趣的投放活动,这是移动营销场景里常见的情况。为了解决这个问题,我们引入adaptive breadth函数来重新定义上述解耦机制。对于节点u对其邻居节点v的adaptive breadth分数为:
然后使用得到的邻居分数来重新定义解耦向量:
上述过程构成了一个adaptive & disentangled layer,叠加L次这样的layer我们就可以捕捉到L-hops的邻居信息,从而生成最终解耦的用户以及营销活动的embeddings。
在线KD-AE模型
给定一个新的投放活动,基于AD-GNN生成的user embedding,在线KD-AE模型负责产出人群定向结果。传统人群定向方法将给定的投放种子人群视为正例,随机采样非种子用户作为负例,然后训练一个分类器(例如:LR, GBDT和DNN等),然而这种方法没有考虑到给定的种子人群(seeds)往往是有偏的。因为种子人群来自于专家经验或者是历史相似投放活动中的转化用户,这样得到的种子用户往往只能代表全量目标人群的部分用户。为了解决这个问题,我们使用知识蒸馏的方式 [5]从离线AD-GNN模型(teacher模型)中提取知识用于指导在线KD-AE模型(student模型)的训练。除了使用传统人群定向模型的训练标签y_h(hard label),KD-AE模型额外包含了从AD-GNN模型得到先验知识,即softened label y_s。基于两类不同的标签,KD-AE模型的损失函数定义为:

其中y_A为KD-AE模型的预测值,Theta_A为模型可训练的参数,数值gamma控制softened label的影响。模型训练完成之后,对准入人群(candidates)进行打分,分数越高则表示该user对当前投放的兴趣越大。从公式我们可以发现,连接teacher模型和student模型的是AD-GNN预测的softened label。下面我们具体介绍softened label的构造方式。
为了构造softened label,我们希望根据种子用户的embedding找到与其最接近的k个历史投放活动(这里利用AD-GNN产出的embedding来计算用户和投放活动的相似性)。但是这种构造softened label的方式计算复杂度较高,特别是当种子人群数量和历史投放活动数量很大时,构造过程会比较耗时。为了加速构造过程,考虑到相似用户对投放活动的喜好也是相似的,我们首先使用k-means对用户进行聚类,计算一个簇中用户嵌入表达的均值作为这个簇的表达,然后对于每个簇找到与其最相似的k个历史投放活动,然后计算与这k个历史投放活动的相似度的均值作为softened label。得到softened label之后,结合是否为种子用户的hard label,我们通过多目标优化的方式就可以训练KD-AE模型了,即上面展示的损失函数。
通过解耦AD-GNN和KD-AE,给定一个新来的定向任务,哈勃平台现在只需要运行一个轻量KD-AE模型,训练时长大幅缩短。较低的时间和计算资源消耗给算法设计带来了更大的空间,在下述第三代算法模型中,我们进一步引入增量学习来提升算法在投放事中的优化能力。
第三代:基于异步GNN+增量学习的audience expansion
上述第二代框架通过离线AD-GNN模型得到了user embedding,然后通过在线KD-AE模型为一次新投放活动圈选合适的用户。流程整体上利用了投放事前的所有历史信息,完成了一次较为无偏的事前人群定向流程。但蚂蚁场景中,常常有一些时间持续较长的人群定向任务,部分任务能有超过一周以上的投放时间。针对此类任务,线上投放系统能够每日回流投放活动的反馈数据,如人群的曝光点击等,但第二代框架对这类反馈数据并没有进行合理地利用。从业务角度考虑,这类反馈数据是本次投放的真实结果反馈。如果能在投放事中加以利用并动态地对投放人群进行干预,既可以更好地捕获本次投放中真实的人群分布,又可以缓解部分任务种子人群量级较小、投放模型欠拟合的问题。基于这样的考虑,我们设计了一套AD-GNN+增量学习体系的通用事中优化流程,对先验的专家经验(种子人群)与实际的投放反馈(曝光点击人群)融合,完成了算法圈人的再次升级。
假设某次活动已经投放了数天,此时我们能够收集到一定数量的反馈数据。这里我们可以使用点击用户和曝光未点击用户分别构建正负样本,并基于AD-GNN产生的embedding训练一个轻量的分类器M1。M1虽然能够很好地分类本次投放的反馈数据,但受事前圈人模型的影响,尤其在投放最初的几天反馈数据量级较少时,极容易存在coverage bias的问题。下图具体展现了两个实际投放中,不同天数上的点击用户在embedding space上的分布存在明显差异,这导致分类器M1直接应用于candidates人群会造成较大偏差。

因此,在历史投放反馈数据的基础上,我们额外引入数量充足的seeds人群来降低coverage bias带来的影响。但是将反馈数据和seeds人群融合在一起的一大难点就是:seeds人群的质量在不同投放上存在明显差异,这需要我们能够根据seeds人群的质量自适应地调节seeds人群在圈人模型中的权重。为此,我们这里基于meta-learning的方式构建了一个meta-learner来学习seeds人群的权重函数V。首先我们将反馈数据F按照时间先后顺序切分为F_train和F_meta,然后根据权重函数V加权的seeds人群和反馈数据F_train,训练得到最优的模型f,而在F_meta上,我们将通过调节权重函数V来最优化f在F_meta上的性能,即对应的目标函数为:

其中

为了最优化上述目标函数,我们采用了[6]中提出的在线更新策略。最终得到的f能够很好融合seeds人群和投放反馈的信息,在提升时效性的同时,很好地缓解了coverage bias的问题。
参考文献
[1] deWet, Stephanie, and Jiafan Ou. "Finding Users Who Act Alike: Transfer Learning for Expanding Advertiser Audiences." Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019.
[2] Ma, Qiang, et al. "Score Look-Alike Audiences." 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW). IEEE, 2016.
[3] Liu, Yudan, et al. "Real-time Attention Based Look-alike Model for Recommender System." Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019.
[4] Huang, Po-Sen, et al. "Learning deep structured semantic models for web search using clickthrough data." Proceedings of the 22nd ACM international conference on Information & Knowledge Management. 2013.
[5] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 (2015).
[6] Shu, Jun, et al. "Meta-weight-net: Learning an explicit mapping for sample weighting." arXiv preprint arXiv:1902.07379 (2019).
蚂蚁智能引擎技术事业部实习生招聘
关于我们:
蚂蚁智能引擎技术事业部是基于大数据和人工智能来支撑蚂蚁所有的业务,包括支付、微贷、征信、安全风控、保险、智能营销等。我们致力于用技术推动包括金融服务业在内的全球现代服务业的数字化升级,携手合作伙伴为消费者和小微企业提供普惠、绿色、可持续的服务,为世界带来微小而美好的改变。
我们的技术为蚂蚁亿级用户、千万级别商户带来世界一流的智能化推荐与搜索体验,为数字化生活业务的升级与持续化增长提供极其重要的数据、算法、计算的支撑。我们在帮助蚂蚁金服各项业务飞速发展的同时,瞄准世界一流的AI水平进行研发,领域包括自然语言处理、智能对话技术、计算机视觉、语音识别等方面。
我们拥有全世界最大规模的金融场景,拥有世界一流的人才储备,包括IEEE fellow、国家/省“千人计划”、MITTR35的顶级技术专家,Google/YouTube/微软Bing/Uber/Netflix的资深技术海归们,本土BAT的百战精英,国内外各种大数据竞赛获大奖的佼佼者,以及阿里星A-Star顶尖应届校招生等等。
我们的技术优势
蚂蚁智能引擎的核心技术包括人工智能、知识图谱、数据智能、商业决策引擎(推荐/搜索/营销/广告)、计算及技术基础设施等领域,这些能力全面贯穿业务运营,安全高效地支持海量业务,服务超过十亿消费者和数千万小微经营者,并助力众多合作伙伴高效地提供产品和服务。
人工智能:我们在人工智能领域持续投入深耕,尤其是在机器学习、自然语言处理、人机对话、共享智能和时序图智能等关键方向,研发目标是进一步增强智能化水平,同时降低AI应用的落地门槛。蚂蚁的各项AI技术能力也受到业界的多方肯定,多次获得行业的重要奖项,如吴文俊人工智能科学技术一等奖,CCF科学技术奖科技进步卓越奖等。
商业决策引擎:通过分析消费者以及商家的特征,借助海量消费者和商家洞察来绘制准确的客户画像,结合从数据到模型端到端一体化工程平台,打造自动特征发现,自动特征工程、模型参数调优和自动模型训练的能力,全面驱动构建了蚂蚁多个业界领先的商业决策系统,包括智能推荐/搜索/广告、全域营销增长、智能投顾/理赔等。
加入我们,您将收获:
-一流的专业能力:技术能力可以得到加速提升,将有大量做技术创新和突破的机会,将具备在亿级别用户、千万级别商户的大规模实战环境下的数据、算法、工程应用经验
-上佳的工作环境:我们注重团队合作、开放、透明的工作环境,使我们的员工能取得杰出的成绩。
-广阔的成长空间:我们提供各式各样具挑战性的任务、培训学习机会、职业发展道路以及晋升发展的机会
招聘岗位
算法工程师:机器学习、自然语言处理、计算机视觉、运筹优化、算法工程
研发工程师:研发工程师(C++/Java)、客户端开发工程师、数据研发工程师、基础平台研发工程师
面向对象:2021.11-2022.10期间应届毕业生
工作地点:杭州、上海
招聘邮箱:simeng.wsm@antgroup.com
特别提醒:本网内容转载自其他媒体,目的在于传递更多信息,并不代表本网赞同其观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,并请自行核实相关内容。本站不承担此类作品侵权行为的直接责任及连带责任。如若本网有任何内容侵犯您的权益,请及时联系我们,本站将会在24小时内处理完毕。




















 基于图神经网络的
基于图神经网络的 百度飞桨框架2.0
百度飞桨框架2.0 擎朗智能邀您参加
擎朗智能邀您参加 爱回收大数据:黑鲨
爱回收大数据:黑鲨 智库云携手歙县,打
智库云携手歙县,打 爱奇艺与新加坡电
爱奇艺与新加坡电 傲林科技李欣:数智
傲林科技李欣:数智 政企合作、行业赋
政企合作、行业赋