【2019年4月3日,北京,微软(亚洲)互联网工程院】
今天,我们很高兴地宣布,微软小冰基于深度神经网络的歌唱模型,已顺利完成V5新版本的研发。新的V5模型实现了重大突破,它使微软小冰第一次能够像人类歌手一样,使用充沛的“中气”来烘托演唱,从而将人工智能虚拟歌声质量提升至新的高度。此外,该模型不仅限于优化微软小冰的声音,还支持对任何人类歌手的声线进行学习、模拟和建模,演绎与再现歌手们巅峰状态下的演唱水平。作为技术示例,我们与日本唱片公司AVEX合作发行的新模型DEMO曲《最高新记忆》,也于今天同时公布。
微软小冰是一个覆盖对话、多重交互感官与内容服务生成的完整人工智能基础框架。其中,“人工智能创造”(AI Creation)是该框架的主要分支之一,它通过我们所研发与持续更新的人工智能技术,大规模学习并掌握人类文字、音乐、绘画等内容创造能力,再发挥人工智能的稳定性及高并发特点,为内容产业的未来变革蓄势。我们将在今年五月召开微软小冰人工智能创造的年度说明会,今天的新版本歌唱模型及DEMO曲,是该说明会的若干前置披露之一。
我们很高兴与行业分享微软(亚洲)互联网工程院在深度神经网络歌唱模型方面的最新进展。中国古时不乏对音乐之声的精辟论述,例如“丝(丝弦乐器)不如竹(管乐器),竹不如肉(人声)”,为其“渐进自然”。因此,我们把不断趋近人类歌手的声音合成质量,视为“人工智能创造”分支的最高技术目标。在上一个版本中,实现了小冰在虚拟演唱中的自然换气。今天推出的新版本,则进一步将“气息”应用于演唱全过程,使生成的歌声接近专业人类歌手,并可预测并自由切换演唱技巧,突破了传统单元拼接技术音高与音准的“软件乐器”标准。我们用DEMO曲来表现这一技术对照的明显差距,请重点关注歌曲时间轴上的以下时刻:
00:31,01:12,01:23,03:14,04:08
V5新模型还具有许多其他技术特征。例如实现了多声部的合成技术,使人工智能歌手可以在不同声部间自然切换,用多个声音来源组成新的虚拟歌手等。建模过程中,所需的训练数据量较上一个版本减少了70%。从技术角度,新模型可针对任何人声建模,形成丰富多彩的人工智能歌手阵营。为此,我们在DEMO曲中特意回避了微软小冰的声音,而是采用另一个声音(日本版小冰凛菜)来演绎。
最后,我们也很高兴地宣布,小冰凛菜(りんな)已与日本最大唱片公司AVEX正式签约,成为滨崎步、安室奈美惠等著名人类歌手的同门师妹。在小冰框架的技术支持下,将涌现出更多具备高还原度的人工智能歌手。微软小冰只是他们的最初雏形。
感谢您的关注。敬请期待微软(亚洲)互联网工程院的后续技术发布。
了解技术DEMO曲《最高新记忆》,请访问:https://www.bilibili.com/video/av48064392或https://www.youtube.com/watch?v=_NPyt1AYUTg
了解小冰凛菜(りんな)在AVEX的演艺动态,请访问:https://avexnet.jp/contents/music_j/RINNA/
特别提醒:本网内容转载自其他媒体,目的在于传递更多信息,并不代表本网赞同其观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,并请自行核实相关内容。本站不承担此类作品侵权行为的直接责任及连带责任。如若本网有任何内容侵犯您的权益,请及时联系我们,本站将会在24小时内处理完毕。













 用肩膀守护“最后
用肩膀守护“最后 手机壁纸分享:你想
手机壁纸分享:你想 设计理念超前!MAX
设计理念超前!MAX 云天励飞首席科学
云天励飞首席科学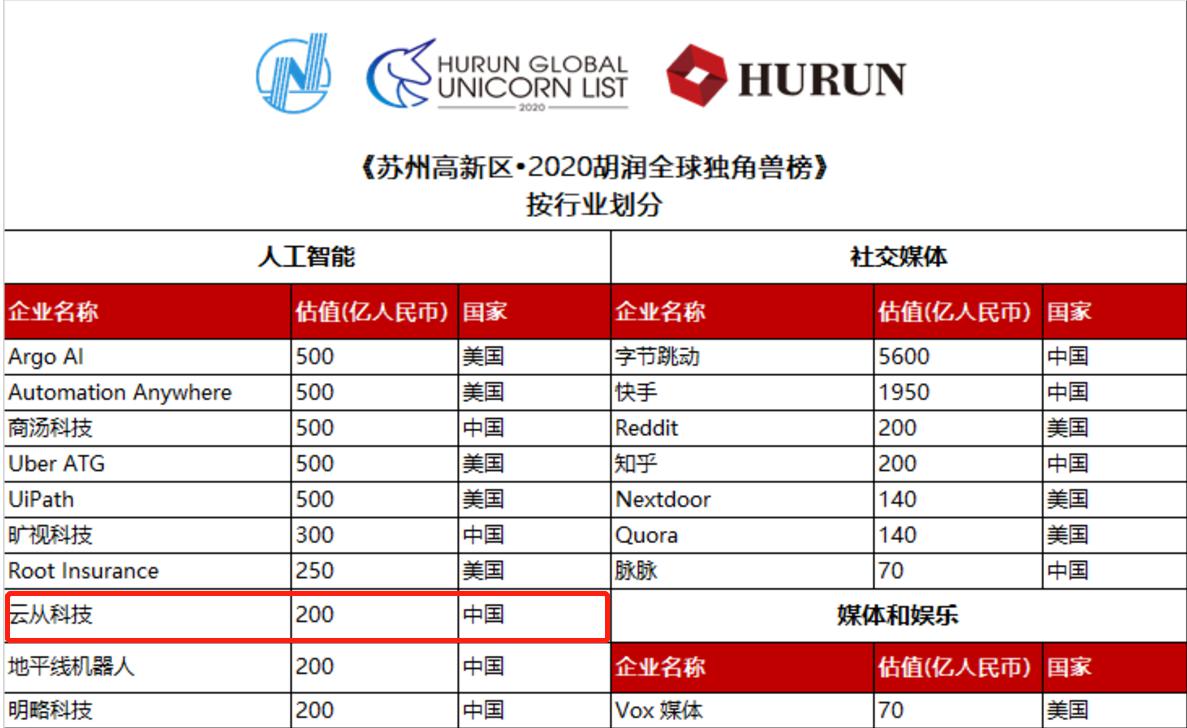 估值200亿荣登独
估值200亿荣登独 网络安全 意识为
网络安全 意识为 ALB专访好丽友法
ALB专访好丽友法 ISC 2020 信创安
ISC 2020 信创安 谷歌 Chrome 浏览
谷歌 Chrome 浏览 驱动人生 神操作
驱动人生 神操作 鱼塘软件|电商“
鱼塘软件|电商“ Win10 设备管理器
Win10 设备管理器 消息称 NVIDIA 定
消息称 NVIDIA 定 “大招”傍身,作业
“大招”傍身,作业 金山办公赋能广西
金山办公赋能广西 软件业迎政策东风
软件业迎政策东风