随着深度学习的迅猛发展,计算机视觉已成为人工智能领域影响最深远的技术之一。在计算机视觉领域深入研究、有着强大技术积累的百度,以17篇论文入选计算机视觉和模式识别大会CVPR 2019,其不俗成绩再次成为国际视觉顶级盛会中受瞩目的“中国面孔”。
据了解,CVPR 2019即将于6月在美国长滩召开,作为人工智能领域计算机视觉方向的重要学术会议,CVPR每年都会吸引全球最顶尖的学术机构和公司的研究人员投稿。
CVPR官网显示,今年有超过5165篇的大会论文投稿,最终录取1299篇,录取率约为25%。据了解,去年的CVPR 2018共有979篇论文被主会收录,录用率约为29%。相比2018,今年的竞争更加激烈。
今年百度公司有17篇论文被CVPR接收,内容涵盖了语义分割、网络剪枝、ReID、GAN等诸多方向,以下为百度入选CVPR 2019的17篇论文。
1)Taking A Closer Look at Domain Shift: Category-level Adversaries for Semantics Consistent Domain Adaptation
论文作者:Yawei Luo; Liang Zheng; Tao Guan; Junqing Yu; Yi Yang
论文介绍:在虚拟图像集(源域)上训练出的语义分割网络,往往在真实图像集(目标域)上表现不佳。网络分割性能下降是由于两个域间存在较大差异,而深度模型泛化能力不足。传统方法尝试通过全局对齐源域和目标域间特征分布的来解决此问题,而该类方法往往忽略了特征间的局部语义一致性。本文首次结合了联合训练和对抗训练来处理此问题。不同于传统方法,本文根据每一个特征的语义对齐程度,自适应的调整特征对齐的力度。该方法解决了传统方法中特征语义不一致问题和负迁移的问题。实验结果证明我们的方法能大大提高网络在目标域图像上的分割精度。
应用场景:自动驾驶。本方法将电脑合成图像训练出的网络直接泛化到现实数据集上,大大减少了自动驾驶领域中街景数据采集和数据标注的工作量。
论文地址:
https://arxiv.org/abs/1809.09478
2)Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration
论文作者:Yang He, Ping Liu, Ziwei Wang, Zhilan Hu, Yi Yang
论文介绍:在本文中,我们分析了关于网络剪枝的“小范数 -低重要性”的标准。以前的工作利用“小范数 -低重要性”的标准来修剪在卷积神经网络中具有较小范数值的滤波器,但出它的有效性取决于两个并不总是满足的要求:(1)滤波器的范数的标准差应该很大; (2)滤波器的最小范数应该很小。为了解决这个问题,我们提出了一种新的滤波器修剪方法,即通过"几何平均数"进行滤波器剪枝,以便在不考虑这两个要求的情况下对模型进行压缩,我们称之为FPGM。与之前的方法不同,FPGM通过去掉冗余的滤波器来压缩CNN模型,而不是去掉那些范数小的过滤器。我们在图像分类任务上的两个数据集上,验证了FPGM的有用性。在Cifar-10数据集上,FPGM在ResNet-110上的计算量降低了52%以上,相对精确度提高了2.69%。此外,在ILSVRC-2012数据集上,FPGM还在ResNet-101上减少了超过42%的计算量。
应用场景:本文提出的方法能够有效提升神经网络压缩率。可以将压缩后的网络部署到便携式设备,比如手机、摄像机等,加快处理速度。
论文地址:
https://arxiv.org/abs/1811.00250
GItHub地址:
https://github.com/he-y/filter-pruning-geometric-median
3)Detailed Human Shape Estimation from a Single Image by Hierarchical Mesh Deformation
论文作者:Hao Zhu; Xinxin Zuo; Sen Wang; Xun Cao; Ruigang Yang
论文介绍:本文提出了一个新的框架,可以根据单个图像恢复详细的人体形状。由于诸如人体形状、身体姿势和视角的变化等因素,因而这是一项具有挑战性的任务。现有方法通常尝试使用缺少表面细节的基于参数的模板来恢复人体形状。因此,所得到的身体形状似乎没有衣服。在本文中,我们提出了一种新颖的基于学习的框架,它结合了参数模型的鲁棒性和自由3D变形的灵活性。我们使用深度神经网络在层次网格变形(HMD)框架中利用身体关节、轮廓和每像素着色信息的约束来细化3D形状。我们能够恢复除皮肤模型之外的详细人体形状。实验证明,我们的方法优于先前的最先进方法,在2D IoU数和3D度量距离方面实现了更好的准确性。
论文地址:
https://arxiv.org/abs/1904.10506v1
GItHub地址:
https://github.com/zhuhao-nju/hmd.git
4)GA-Net: Guided Aggregation Net for End-to-end Stereo Matching
论文作者:Feihu Zhang; Victor Adrian Prisacariu; Yang Ruigang; Philip Torr
论文介绍:在立体匹配任务中,为了准确估计差异,匹配成本聚合在传统方法和深度神经网络模型中都是至关重要的。我们提出了两个新的神经网络层,分别用于捕获局部和整个图像的成本相关性。第一个是半全局聚合层,它是半全局匹配的可微近似;第二个是局部引导聚合层,它遵循传统的成本过滤策略来细化薄结构。这两层可以用来代替广泛使用的3D卷积层,该层由于具有立方计算/存储器复杂性而计算成本高且消耗存储器。在实验中,我们表明,具有双层引导聚合块的网络很轻易地超过了具有19个3D卷积层的最先进的GC-Net。我们还训练了深度引导聚合网络(GA-Net),它比场景流数据集和KITTI基准测试中的最新方法具有更好的准确性。
论文地址:
https://arxiv.org/abs/1904.06587
GitHub地址:
https://github.com/feihuzhang/GANet
5)Invariance Matters: Exemplar Memory for Domain Adaptive Person Re-identification
论文作者:Zhun Zhong, Liang Zheng, Zhiming Luo, Shaozi Li, Yi Yang
论文介绍:本论文旨在解决行人再识别中的跨数据集问题:利用有标注的源数据集和无标注的目标数据集学习一个在目标数据集具有很好的鲁棒性的模型。主流的研究方法主要通过降低源域和目标域之间的特征分布的差异。然而,这些方法忽略了目标域的域间变化,这些变化中包含了影响目标域测试性能的重要因素。在本文的工作中,我们全面的探讨了目标域中的域间变化,并基于三种潜在的域内不变性(样例不变性,相机不变性和领域不变性)提出了一个新的模型泛化方法。为了实现这个方法,我们在模型训练过程中引入了一个样例记忆模块用以存储目标数据在训练过程中的中间特征。该样例记忆模块可以使我们快速的计算目标域中局部训练样本和全局样本的相似性,同时有效的在模型训练中加入提出的三个不变性限制。实验证明本文提出的三个不变性性质对提升领域适应的性能是不可或缺的。同时,我们的方法在三个行人再识别的目标域中的准确率大大的超过了当前现有的方法。
应用场景:本文提出的方法能够有效提升行人再识别模型在跨场景下的泛化能力。使得我们可以在现有的标注数据情况下,以无监督的方式提升模型在新的场景下的性能。
论文地址:
https://arxiv.org/abs/1904.01990
GitHub地址:
https://github.com/zhunzhong07/ECN
6)Searching for A Robust Neural Architecture in Four GPU Hours
论文作者:Xuanyi Dong, Yi Yang
论文介绍:本论文旨在解决神经网络搜索算法消耗GPU资源过大的问题。目前很多神经网络搜索算法在小数据集CIFAR上,都需要消耗成百上千的GPU/TPU。为了提高神经网络的搜索效率,我们提出了一种利用可微网络结构采样器的基于梯度的搜索方法。我们的方法将整个搜索空间用一个有向无环图来表示,这个图包含了成百万多个子图,每一个子图都代表了一种网络结构。针对这个有向无环图,我们设计了一个可微的采样器,利用Gumbel-Softmax技术将离散的采样过程变成可微可导的;在训练过程中,通过验证集上的目标损失函数来优化这个采样器,使得采样器最终能过获得一个性能较好的网络结构。在实验中,我们在一个GPU上,通过几个小时的搜索时间,就可以在CIFAR上找到一个高性能的网络结构。
应用场景:本文提出的方法能够有效地在较短时间利用少量GPU搜索出鲁棒的网络结构,可以广泛地应用在大部分任务里,搜索出对更小更快精度更高的网络模型。
GitHub地址:
https://github.com/D-X-Y/GDAS
7)DM-GAN: Dynamic Memory Generative Adversarial Networks for Text-to-image Synthesis
论文作者:Minfeng Zhu, Pingbo Pan, Wei Chen, Yi Yang
论文介绍:本论文旨在提升基于文本生成的图片的真实性。当前的方法都是先生成比较粗糙的初始图像,然后再优化图像从而生成高分辨率的真实图像。然而,目前大多数方法仍存在两个问题:(1)当前方法的结果很大程序上取决于初始图像的质量。如果初始图像质量不高,则第二阶段优化很难将图像优化到令人满意的程度。(2)每个单词对于不同的图片内容都有不同的信息量,但当前方法在两个阶段中仍然保持了相同的单词重要性。
在本文工作中,我们提出动态记忆生成对抗网络(DM-GAN)来生成高质量的图片。我们提出了一个动态记忆模块来优化粗糙的初始图像,即使初始图像生成不良,它也可以生成高质量的图像。具体来说,动态记忆模块包括一个根据初始图像选择重要文本信息的记忆写入门和一个自适应融合图片特征和文本信息的反馈门。我们在COCO和CUB数据集上评估了我们的模型。实验结果表明,我们的方法在FID和IS指标以及真实性上都超过了当前方法。
应用场景:文本提出的方法可以显著提升基于文本生成图片的真实性,我们可以实现文章自动配图等功能,可以大大降低创作者的配图成本。
论文地址:
https://arxiv.org/abs/1904.01310
8)Sim-Real Joint Reinforcement Transfer for 3D Indoor Navigation
论文作者:Fengda Zhu, Linchao Zhu, Yi Yang
论文介绍:在室内3D导航中,环境中的机器人根据指令移动到目标点。但是在物理世界中部署用于导航的机器人,需要大量的培训数据来学习有效的策略。为机器人训练获得足够的真实环境数据是代价昂贵的,因此我们提出通过合成数据渲染环境随后将策略迁移到真实环境中。虽然合成环境有利于来促进现实世界中的导航训练,但真实环境与合成环境有两个方面不同。首先,两种环境的视觉表示具有显着的差异。其次,两个环境的房屋计划有很大不同。因此,需要在强化模型中调整两种类型的信息,即视觉表示和策略行为。视觉表征和策略行为的学习过程是互惠的。
我们提出联合调整视觉表现和策略行为,以实现环境和策略的相互影响。具体来说,我们的方法采用了用于视觉表征转移的对抗特征适应模型和用于策略行为模仿的模拟策略。实验结果表明,我们的方法在没有任何额外的人类注释的情况下优于基础模型高达21.73%。
应用场景:本文提出的视觉特征适应模型和策略模拟模型可以有效将机器人在虚拟环境中学习到的策略和特征迁移到实际场景中,有利于导航机器人,无人车等需要大量数据训练的应用在缺乏复杂场景的真实数据时,通过渲染环境获得更好的策略。
论文地址:
https://arxiv.org/abs/1904.03895
9)Contrastive Adaptation Network for Unsupervised Domain Adaptation
论文作者:Guoliang Kang, Lu Jiang, Yi Yang, Alexander G. Hauptmann
论文介绍:无监督域适应旨在利用带标签源域数据和无标签目标域数据,获得在目标域数据上的优良的预测性能。以往的方法在消除域差异的过程中没有充分利用类别信息,导致对齐错误,影响泛化性能。为了解决这些问题,这篇文章提出了新的域差异度量指标 “对比域差异” 来刻画类内和类间域差异,并且提出 “对比适应网络” 来优化这个指标。我们设计了新的类感知采样方法,采用交替更新的方式端到端地优化我们的网络。我们在两个标准数据集上取得了比现有的方法更好的性能。
应用场景:可以提高单一场景训练模型在缺乏标签的新场景下的识别性能,如利用人工合成带标签数据集,在实际场景图片上进行识别等任务。
论文地址:
https://arxiv.org/abs/1901.00976
10)ApolloCar3D: A Large 3D Car Instance Understanding Benchmark for Autonomous Driving
论文作者:Xibin Song, Peng Wang, Dingfu Zhou, Rui Zhu, Chenye Guan, Yuchao Dai, Hao Su, Hongdong Li, Ruigang Yang
亮点介绍:(1)本文提出了目前已知自动驾驶领域最大规模的三维车辆姿态数据集,共包含5000+高分辨率图像(3384*2710)、6万+车辆的三维姿态信息及对应的车辆二维语义关键点信息。图像中每辆车使用工业级高精度的三维车辆模型进行三维与二维的匹配获取车辆姿态。本数据集的规模是目前自动驾驶领域相关数据集的20倍左右,如PASCAL3D+,KITTI等;(2)基于此数据集,本文提出了不同的方法进行车辆三维姿态估计,包括基于关键点的方法和非关键点的方法;(3)本文提出了完整的车辆三维信息评估方法,包括车辆的形状和姿态信息,相比目前自动驾驶领域相关数据集的评估标准,本文的评估更加全面。
落地场景:自动驾驶领域,基于单张图像的车辆姿态估计。
论文地址:
https://arxiv.org/abs/1811.12222
11)UnOS: Unified Unsupervised Optical-flow and Stereo-depth Estimation by Watching Videos
论文作者:Yang Wang, Peng Wang, Zhenheng Yang, Chenxu Luo, Yi Yang, and Wei Xu
亮点介绍:只通过双目摄像头的视频,通过深度学习,就能学习到 双目深度视觉,光流和相机姿态。
落地场景:可以辅助支持自动驾驶双目视觉模型,从而更好的从激光的离散深度变换到稠密深度。
论文地址:
https://arxiv.org/abs/1810.03654
12)Look More Than Once: An Accurate Detector for Text of Arbitrary Shapes
论文作者:Chengquan Zhang, Borong Liang, Zuming Huang, Mengyi En, Junyu Han, Errui Ding, Xinghao Ding
亮点介绍:受限于神经网络感受野大小约束和简单的文字包围盒表达(比如矩形框或四边形),以往的文字检测器在长词和任意形状的文字场景容易失败。本文提出了一个新的文字检测器框架,针对性的解决了这两个问题。新的文字检测器框架由三部分组成,直接回归器(Direct Regressor, DR)、迭代改善模块(Iterative Refinement Module, IRM)和文字形状表达模块(Shape Expression Module, SEM)。
DR输出四边形表达的文字检测候选;IRM基于四边形对应的特征块逐步感知和改善完整的四边形文字包围盒以解决长词检测问题;SEM模块则通过回归完整四边形候选框内的文字实例几何信息,来重建更加精准的上下顶点线对称的多边形文字表示。IRM和SEM作为可学习的和可插入的模块,能够联合DR一起进行端到端的训练。在包含多方向、长词、任意弯曲和多语种场景的五个具有权威性的公开数据集合(ICDAR2017-RCTW, SCUT-CTW1500, Total-Text, ICDAR2015 and ICDAR17-MLT)上,我们提出的新检测器和所有已公开论文中的纯检测方法作对比指标都达到了最好的效果(SOTA)。
论文地址:
https://arxiv.org/abs/1904.06535
13)STGAN: A Unified Selective Transfer Network for Arbitrary Image Attribute Editing
论文作者:Ming Liu, Yukang Ding, Min Xia, Xiao Liu, Errui Ding, Wangmeng Zuo, Shilei Wen
亮点介绍:提出了STGAN方法用于图片/视频的端到端属性转换。对传统方法提出了两点改进:1) 在自编码网络结构中引入选择性属性编辑单元强化了属性编辑的效果 ;2) 提出了基于属性更改的训练机制。在celebA数据集上转换效果全方位好于已有方法。
落地场景:视频拍摄特效、物料样式生成。
论文地址:
https://arxiv.org/abs/1904.09709
GitHub地址:
https://github.com/csmliu/STGAN
14)Attentive Feedback Network for Boundary-Aware Salient Object Detection
论文作者:Mengyang Feng, Huchuan Lu, and Errui Ding
论文介绍:最近基于深度学习的显著目标检测方法在完全卷积神经网络(FCN)的基础上实现了可喜的性能。然而,他们中的大多数都遭受了边界挑战。目前最先进的方法采用特征聚合技术,并且可以精确地找出其中的显著目标,但是它们经常无法将具有精细边界的整个对象分割出来,尤其是那些凸起的窄条纹。因此,基于FCN的模型仍有很大的改进空间。在本文中,我们设计了注意反馈模块(AFM),以更好地探索对象的结构。我们还采用边界增强损失(BEL)进一步学习精细边界。我们提出的深度模型在目标边界上获得了令人满意的结果,并在5个广泛测试的显著目标检测基准上实现了最先进的性能。该网络采用完全卷积方式,以26 FPS的速度运行,不需要任何后期处理。
论文地址:
https://github.com/ArcherFMY/AFNet
15)A Mutual Learning Method for Salient Object Detection with intertwined Multi-Supervision
论文作者:Runmin Wu, Mengyang Feng, Wenlong Guan, Dong Wang, Huchuan Lu, Errui Ding
论文介绍:尽管近来深度学习技术在显著目标检测方面取得了很大进展,但由于目标的内部复杂性以及卷积和池化操作中的步幅导致的不准确边界,预测的显著图仍然存在不完整的预测。为了缓解这些问题,我们建议通过利用显著目标检测,以及前景轮廓检测和边缘检测的监督来训练显著性检测网络。首先,我们以交织的方式利用显著目标检测和前景轮廓检测任务来生成具有均匀高光的显著图。其次,前景轮廓和边缘检测任务同时相互引导,从而导致精确的前景轮廓预测并减少边缘预测的局部噪声。此外,我们开发了一种新颖的相互学习模块(MLM),它作为我们方法的构建模块。每个MLM由多个以相互学习方式训练的网络分支组成,性能得意大大提高。我们对七个具有挑战性的数据集进行的大量实验表明,我们所提出的方法在显著目标检测和边缘检测方面都能达到最好的效果。
GitHub地址:
https://github.com/JosephineRabbit/MLMSNet
16)L3-Net: Towards Learning based LiDAR Localization for Autonomous Driving
论文作者:Weixin Lu, Yao Zhou, Guowei Wan, Shenhua Hou, Shiyu Song
亮点介绍:自定位模块是无人车系统的基础模块之一,一个成熟的L4级别无人车定位系统需要提供厘米级定位精度的输出结果。百度提出了一种基于学习的点云定位技术,不同于传统的人工设计的复杂算法,该技术对传统的定位方法进行拆解,使用深度学习网络来取代传统的各个环节和步骤,并在一个包含多种场景路况和大尺度时间跨度的数据集上验证了算法效果,实现了厘米级的定位精度。该方案是全球范围内,业界首次通过使用直接作用于激光点云的深度学习网络来解决自动驾驶的自定位问题。数据集包含了城市道路、园区道路和高速等多种富有挑战的路况场景,数据总里程达380km,即将在百度Apollo平台开放。
落地场景:百度无人车
论文地址:
https://songshiyu01.github.io/publication/cvpr2019_localization/
17)Improving Transferability of Adversarial Examples with Input Diversity
论文作者:Cihang Xie; Yuyin Zhou; Song Bai; Zhishuai Zhang; Jianyu Wang; Zhou Ren; Alan Yuille
论文介绍:尽管CNN已经在各种视觉任务上取得了非常好的表现,但它们很容易受到对抗性示例的影响,这些示例是通过在清晰的图像中加入人类不易察觉的扰动而精心制作的。然而,大多数现有的对抗性攻击在具有挑战性的黑盒设置下只能获得相对较低的成功率,因为攻击者不了解模型结构和参数。为此,我们建议通过创建不同的输入模式来提高对抗性示例的可迁移性。我们的方法不是仅使用原始图像来生成对抗性示例,而是在每次迭代时将随机变换应用于输入图像。
ImageNet上的大量实验表明,我们所提出的攻击方法生成的对抗性示例可以比现有基线更好地迁移到不同的网络。通过评估我们针对NIPS 2017对抗性竞争中的顶级防御解决方案和官方基线的方法,增强型攻击的平均成功率达到73.0%,在NIPS竞争中的前1次攻击提交率大幅提高6.6%。我们希望我们提出的攻击策略可以作为评估网络对抗的稳健性和未来不同防御方法的有效性的强大基准基线。
论文地址:
https://arxiv.org/abs/1803.06978
GitHub地址:
https://github.com/cihangxie/DI-2-FGSM
特别提醒:本网内容转载自其他媒体,目的在于传递更多信息,并不代表本网赞同其观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,并请自行核实相关内容。本站不承担此类作品侵权行为的直接责任及连带责任。如若本网有任何内容侵犯您的权益,请及时联系我们,本站将会在24小时内处理完毕。




















 用肩膀守护“最后
用肩膀守护“最后 手机壁纸分享:你想
手机壁纸分享:你想 设计理念超前!MAX
设计理念超前!MAX 云天励飞首席科学
云天励飞首席科学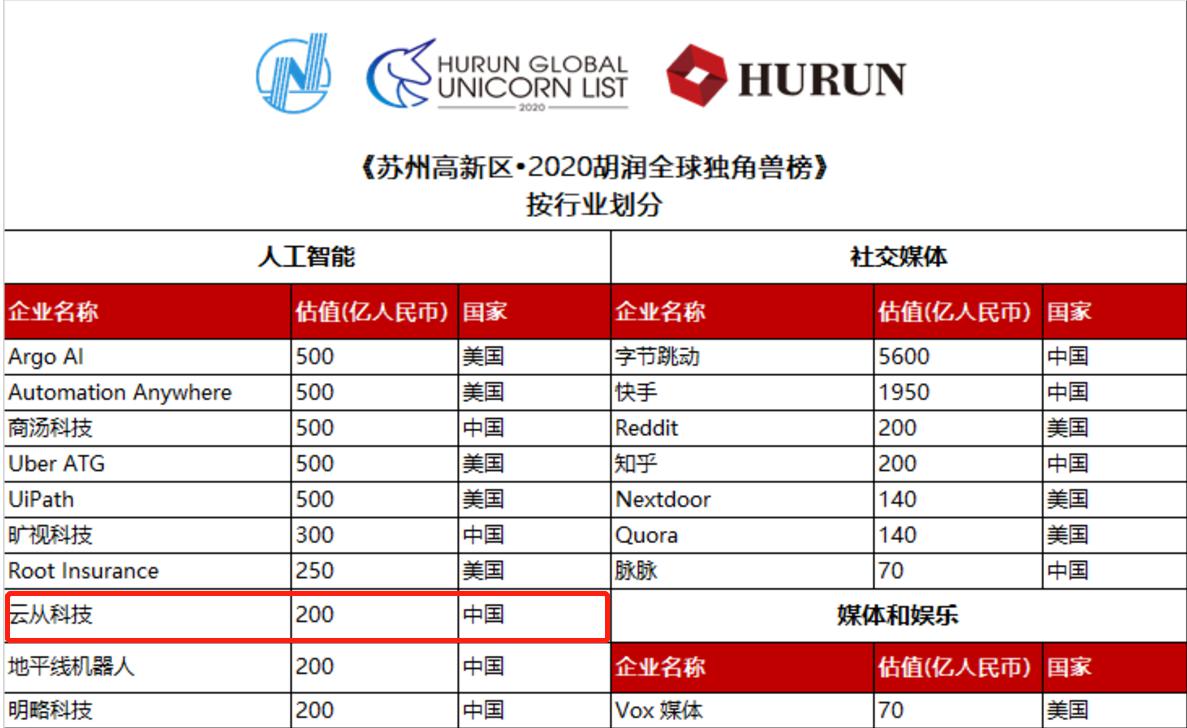 估值200亿荣登独
估值200亿荣登独 网络安全 意识为
网络安全 意识为 ALB专访好丽友法
ALB专访好丽友法 ISC 2020 信创安
ISC 2020 信创安